4 Things You Need to Know about Zerto Virtual Replication 4.0
It’s not every day that you get to announce a milestone release in a product that has been shipping for several years, but that’s what we’re doing with Zerto Virtual Replication 4.0.
Zerto, the standard for business continuity and disaster recovery for virtualized workloads is once again raising the bar. Here are the 4 main things you need to know about Zerto Virtual Replication 4.0.
![1]()
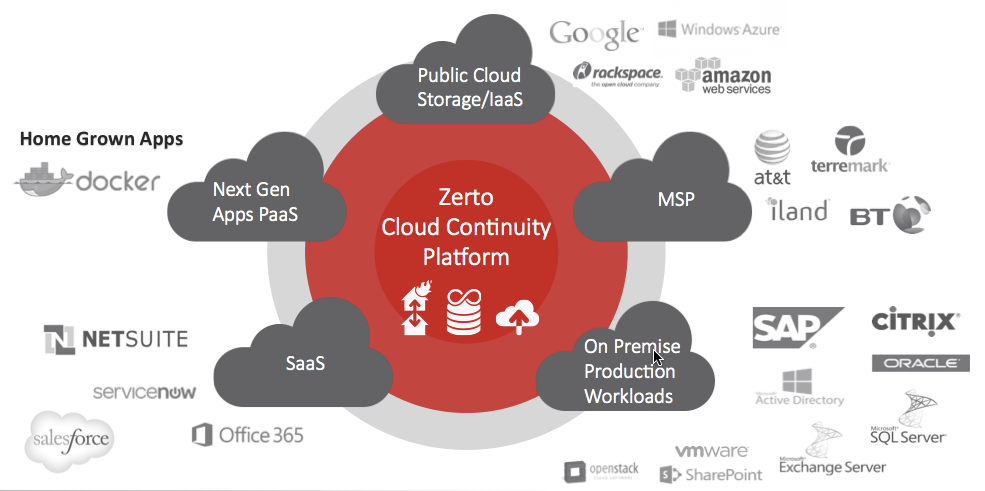
The Zerto Cloud Continuity Platform
Imagine being able to determine your data protection solution by selecting two things:
- The service level uptime expectations of the application
- The costs associated with meeting the service level
Simplifying the choices to the essentials and creating a platform that can support it empowers the entire organization to focus on the business and innovation, not disasters. That is the Zerto Cloud Continuity Platform vision.
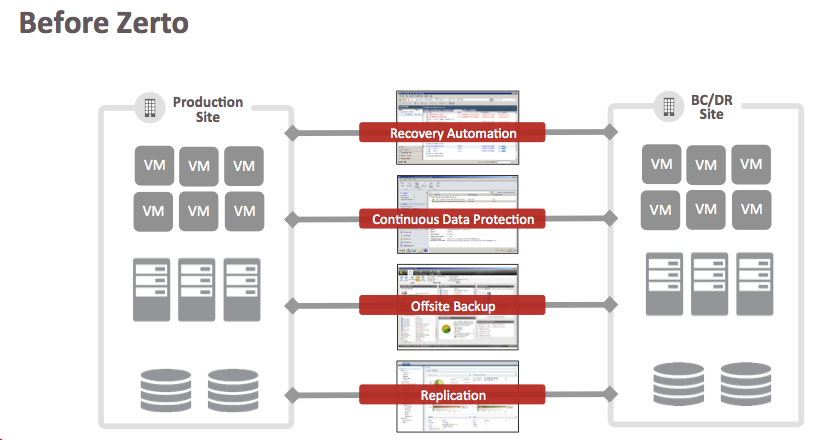
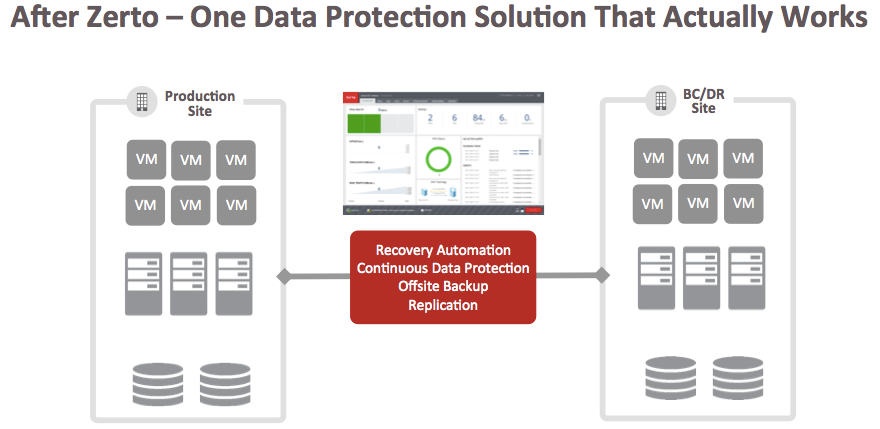
In a fully realized Cloud Continuity Platform model, there is no consideration of the infrastructure that it takes to meet the actual data protection requirements or any business requirements. It shouldn’t matter if the infrastructure includes an all on-premise, public cloud, or a hybrid solution to meet the requirements. The infrastructure should be able to handle it, and it should be easy to install and manage.
![Zerto-Cloud-Continuity-Platform]()
ZVR will be able to federate replication and failover orchestration on them all. We think this is the only realistic way to address the ever-increasing complexity.
Service offerings from private, public, SaaS and PaaS providers will continue to expand and new, interesting technologies such as containerization will always be emerging. The Zerto Cloud Continuity Platform will federate them all to a single logical data protection solution.
It is an exciting vision of what data protection can achieve when it is built upon the replication and orchestration capability of ZVR.
If you have a hypervisor in one datacenter that doesn’t match the hardware or hypervisor in another datacenter, it won’t matter you can still use it. If the cloud makes sense as either the source or target for your data protection design – use it.
For migrations, ZVR 4.0 offers options that you simply didn’t have before. With the non-disruptive testing capability, you can perfect the migration steps well before the actual downtime occurs. This makes for the shortest outages possible.
In ZVR version 4.0, we take the first steps in fulfilling the vision by introducing two new supported platforms and a completely new interface to manage it all.
![2]()
ZVR 4.0 UI: The new face of data protection
Giving you the ability to perform complex replication and complete failover orchestration while keeping an intuitive management interface is in our DNA. But we wanted to provide even more capability from the UI to make it as easy as possible to manage the disparate DR platforms underneath.
We’ve taken years of feedback from large production customers, paired it with our ubiquitous infrastructure goals of the Cloud Continuity Platform and created a completely refactored user interface.
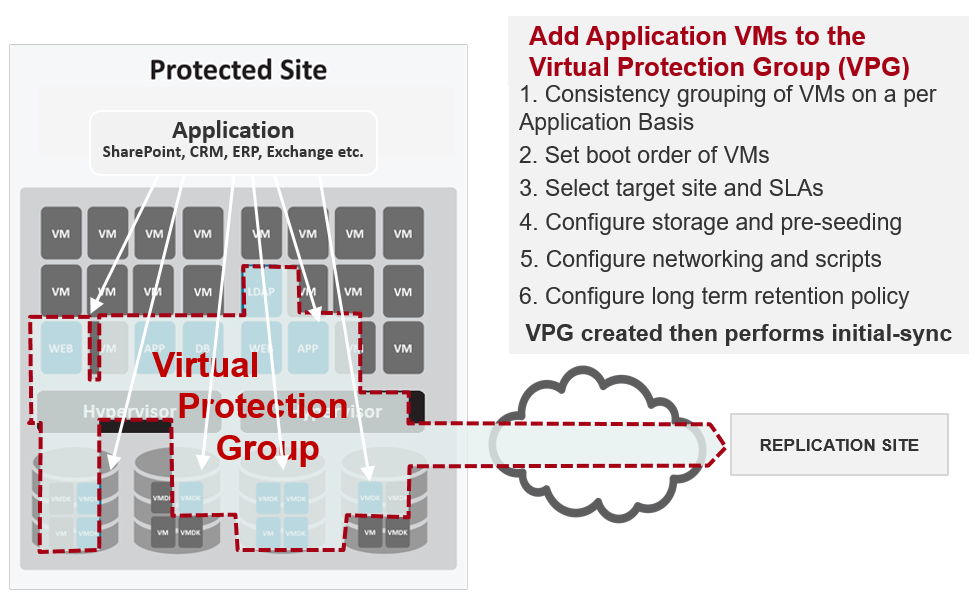
The first thing that greets you is a dashboard with all of your critical information in one view. Key Performance Indicators are right in front of you for quick analysis. Both real-time and historic information are the dashboard and the VPG status is shown as a green, yellow or red heat map of health. All of the creation tasks are now wizard-driven for easier administration.
The new UI is based on HTML5, so you have even more choices of what device you can use to manage your data protection.
![ZVR-4-UI]()
![3]()
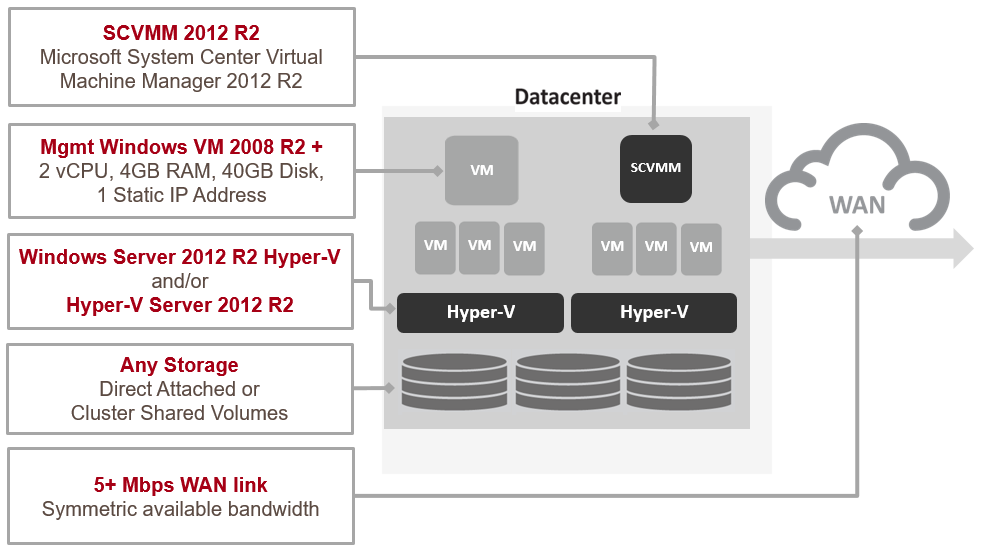
Hypervisor Agnostic: ZVR now supports Microsoft Hyper-V
ZVR 4.0 adds Microsoft Hyper-V support. This includes cross-hypervisor replication between a Microsoft Hyper-V and a VMware vSphere site. This is one of the milestone additions in capability because it is the first step in ZVR being hypervisor agnostic as well as hardware agnostic.
Deployment and management is remarkably similar to what you experience in a VMware-only deployment. In fact, you won’t really know the difference between hypervisors in the Zerto UI. It looks, performs and is managed exactly the same. You may find yourself opening the System Center Virtual Machine Manager (SCVMM) to ensure the VMs were actually failing over to Hyper-V and not vSphere.
Of course, crossing hypervisors comes with some additional things to know about drivers and guest operating systems behavior when failing over. Zerto has made that information readily accessible and makes easier to deploy mixed hypervisor solution.
Support for Microsoft Hyper-V helps you reduce costs by leveraging already owned Hyper-V licenses for DR or for test and development. Zerto makes the conversion of the workload from the Hyper-V environment to the VMware production environment as simple as point and click.
![4]()
DR to the Public Cloud: ZVR supports Amazon Web Services (AWS) as the recovery site with ZVR for AWS 1.0
ZVR now allows you to use AWS as the target site for your DR. Since this is our first public cloud offering, we wanted to highlight that point, so we gave it a 1.0 version number.
You will be able to mix your on premise protection with a public cloud for certain applications that may not need the aggressive RTO and RPOs that on premise solutions offer.
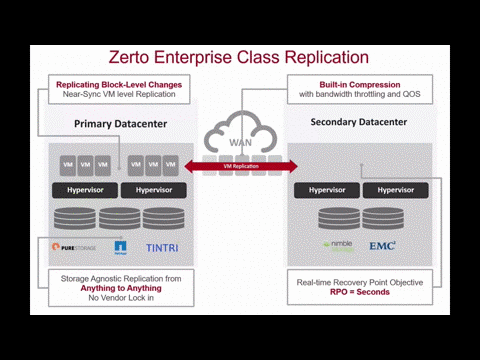
You don’t have to settle for less; ZVR brings our award-winning enterprise class replication and orchestration performance abilities to AWS too. RPOs are measured in seconds and you will see RTOs faster than any other solution.
Along with DR, there are several uses for on premise to AWS including:
- Test/Development to reduce costs
- Eliminate cost of DR site with an OPEX line item
- Migrate to AWS to eliminate hardware maintenance and obtain on demand resources
If you are familiar with the ZVR architecture, the graphic below should look very familiar. Going to AWS shouldn’t mean you have to use different methodologies and tools to use it. With ZVR 4.0, you don’t.
![Zerto-Replication-to-AWS]()
The deployment on the on-premise side is exactly the same as it always has been, plus you can use Hyper-V on the source side as well. In fact, it can be paired with other non-AWS sites at the same time. The virtual machines are placed in to virtual protection groups and the VMs are all protected and have write-order fidelity between them. We still have the 5-day point in time journal for AWS recoveries as well to keep it the same as an on-premise solution.
Try it now!
With all the new features and options, if you haven’t tried ZVR 4.0, we make it really easy.